更换文档检测模型
This commit is contained in:
121
paddle_detection/deploy/fastdeploy/rockchip/rknpu2/README.md
Normal file
121
paddle_detection/deploy/fastdeploy/rockchip/rknpu2/README.md
Normal file
@@ -0,0 +1,121 @@
|
||||
[English](README.md) | 简体中文
|
||||
|
||||
# PaddleDetection RKNPU2部署示例
|
||||
|
||||
## 1. 说明
|
||||
RKNPU2 提供了一个高性能接口来访问 Rockchip NPU,支持如下硬件的部署
|
||||
- RK3566/RK3568
|
||||
- RK3588/RK3588S
|
||||
- RV1103/RV1106
|
||||
|
||||
在RKNPU2上已经通过测试的PaddleDetection模型如下:
|
||||
|
||||
- Picodet
|
||||
- PPYOLOE(int8)
|
||||
- YOLOV8
|
||||
|
||||
如果你需要查看详细的速度信息,请查看[RKNPU2模型速度一览表](https://github.com/PaddlePaddle/FastDeploy/blob/develop/docs/cn/faq/rknpu2/rknpu2.md)
|
||||
|
||||
## 2. 使用预导出的模型列表
|
||||
|
||||
### ONNX模型转RKNN模型
|
||||
|
||||
为了方便大家使用,我们提供了python脚本,通过我们预配置的config文件,你将能够快速地转换ONNX模型到RKNN模型
|
||||
|
||||
```bash
|
||||
python tools/rknpu2/export.py --config_path tools/rknpu2/config/picodet_s_416_coco_lcnet_unquantized.yaml \
|
||||
--target_platform rk3588
|
||||
```
|
||||
|
||||
### RKNN模型列表
|
||||
|
||||
为了方便大家测试,我们提供picodet和ppyoloe两个模型,解压后即可使用:
|
||||
|
||||
| 模型名称 | 下载地址 |
|
||||
|-----------------------------|-----------------------------------------------------------------------------------|
|
||||
| picodet_s_416_coco_lcnet | https://bj.bcebos.com/paddlehub/fastdeploy/rknpu2/picodet_s_416_coco_lcnet.zip |
|
||||
| ppyoloe_plus_crn_s_80e_coco | https://bj.bcebos.com/paddlehub/fastdeploy/rknpu2/ppyoloe_plus_crn_s_80e_coco.zip |
|
||||
|
||||
|
||||
## 3. 自行导出PaddleDetection部署模型以及转换模型
|
||||
|
||||
RKNPU部署模型前需要将Paddle模型转换成RKNN模型,具体步骤如下:
|
||||
|
||||
* Paddle动态图模型转换为ONNX模型,请参考[PaddleDetection导出模型](https://github.com/PaddlePaddle/PaddleDetection/blob/release/2.4/deploy/EXPORT_MODEL.md)
|
||||
,注意在转换时请设置**export.nms=True**.
|
||||
* ONNX模型转换RKNN模型的过程,请参考[转换文档](https://github.com/PaddlePaddle/FastDeploy/blob/develop/docs/cn/faq/rknpu2/export.md)进行转换。
|
||||
|
||||
### 3.1 模型转换example
|
||||
|
||||
#### 3.1.1 注意点
|
||||
|
||||
PPDetection模型在RKNPU2上部署时要注意以下几点:
|
||||
|
||||
* 模型导出需要包含Decode
|
||||
* 由于RKNPU2不支持NMS,因此输出节点必须裁剪至NMS之前
|
||||
* 由于RKNPU2 Div算子的限制,模型的输出节点需要裁剪至Div算子之前
|
||||
|
||||
#### 3.1.2 Paddle模型转换为ONNX模型
|
||||
|
||||
由于Rockchip提供的rknn-toolkit2工具暂时不支持Paddle模型直接导出为RKNN模型,因此需要先将Paddle模型导出为ONNX模型,再将ONNX模型转为RKNN模型。
|
||||
|
||||
```bash
|
||||
# 以Picodet为例
|
||||
# 下载Paddle静态图模型并解压
|
||||
wget https://paddledet.bj.bcebos.com/deploy/Inference/picodet_s_416_coco_lcnet.tar
|
||||
tar xvf picodet_s_416_coco_lcnet.tar
|
||||
|
||||
# 静态图转ONNX模型,注意,这里的save_file请和压缩包名对齐
|
||||
paddle2onnx --model_dir picodet_s_416_coco_lcnet \
|
||||
--model_filename model.pdmodel \
|
||||
--params_filename model.pdiparams \
|
||||
--save_file picodet_s_416_coco_lcnet/picodet_s_416_coco_lcnet.onnx \
|
||||
--enable_dev_version True
|
||||
|
||||
# 固定shape
|
||||
python -m paddle2onnx.optimize --input_model picodet_s_416_coco_lcnet/picodet_s_416_coco_lcnet.onnx \
|
||||
--output_model picodet_s_416_coco_lcnet/picodet_s_416_coco_lcnet.onnx \
|
||||
--input_shape_dict "{'image':[1,3,416,416], 'scale_factor':[1,2]}"
|
||||
```
|
||||
|
||||
#### 3.1.3 编写yaml文件
|
||||
|
||||
**修改normalize参数**
|
||||
|
||||
如果你需要在NPU上执行normalize操作,请根据你的模型配置normalize参数,例如:
|
||||
|
||||
```yaml
|
||||
mean:
|
||||
-
|
||||
- 123.675
|
||||
- 116.28
|
||||
- 103.53
|
||||
std:
|
||||
-
|
||||
- 58.395
|
||||
- 57.12
|
||||
- 57.375
|
||||
```
|
||||
|
||||
**修改outputs参数**
|
||||
|
||||
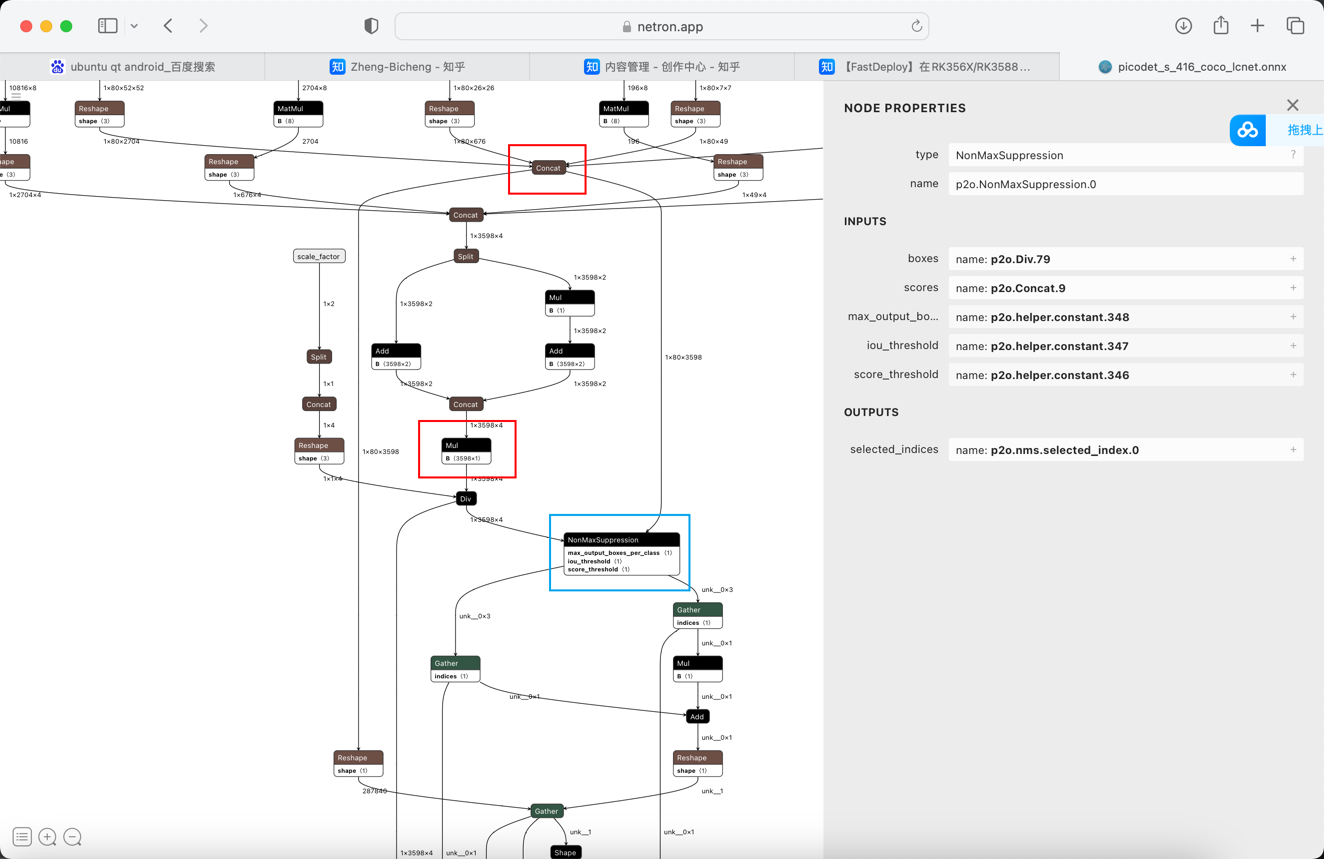
由于Paddle2ONNX版本的不同,转换模型的输出节点名称也有所不同,请使用[Netron](https://netron.app)对模型进行可视化,并找到以下蓝色方框标记的NonMaxSuppression节点,红色方框的节点名称即为目标名称。
|
||||
|
||||
## 4. 模型可视化
|
||||
例如,使用Netron可视化后,得到以下图片:
|
||||
|
||||
|
||||
|
||||
找到蓝色方框标记的NonMaxSuppression节点,可以看到红色方框标记的两个节点名称为p2o.Div.79和p2o.Concat.9,因此需要修改outputs参数,修改后如下:
|
||||
|
||||
```yaml
|
||||
outputs_nodes:
|
||||
- 'p2o.Mul.179'
|
||||
- 'p2o.Concat.9'
|
||||
```
|
||||
|
||||
|
||||
## 5. 详细的部署示例
|
||||
- [RKNN总体部署教程](https://github.com/PaddlePaddle/FastDeploy/blob/develop/docs/cn/faq/rknpu2/rknpu2.md)
|
||||
- [C++部署](cpp)
|
||||
- [Python部署](python)
|
||||
@@ -0,0 +1,11 @@
|
||||
CMAKE_MINIMUM_REQUIRED(VERSION 3.10)
|
||||
project(infer_demo)
|
||||
|
||||
set(CMAKE_CXX_STANDARD 14)
|
||||
|
||||
option(FASTDEPLOY_INSTALL_DIR "Path of downloaded fastdeploy sdk.")
|
||||
|
||||
include(${FASTDEPLOY_INSTALL_DIR}/FastDeployConfig.cmake)
|
||||
include_directories(${FastDeploy_INCLUDE_DIRS})
|
||||
add_executable(infer_demo infer.cc)
|
||||
target_link_libraries(infer_demo ${FastDeploy_LIBS})
|
||||
@@ -0,0 +1,47 @@
|
||||
[English](README.md) | 简体中文
|
||||
# PaddleDetection RKNPU2 C++部署示例
|
||||
|
||||
本目录下用于展示PaddleDetection系列模型在RKNPU2上的部署,以下的部署过程以PPYOLOE为例子。
|
||||
|
||||
## 1. 部署环境准备
|
||||
在部署前,需确认以下两个步骤:
|
||||
|
||||
1. 软硬件环境满足要求
|
||||
2. 根据开发环境,下载预编译部署库或者从头编译FastDeploy仓库
|
||||
|
||||
以上步骤请参考[RK2代NPU部署库编译](https://github.com/PaddlePaddle/FastDeploy/blob/develop/docs/cn/faq/rknpu2/rknpu2.md)实现
|
||||
|
||||
## 2. 部署模型准备
|
||||
|
||||
模型转换代码请参考[模型转换文档](../README.md)
|
||||
|
||||
## 3. 运行部署示例
|
||||
|
||||
```bash
|
||||
# 下载部署示例代码
|
||||
git clone https://github.com/PaddlePaddle/PaddleDetection.git
|
||||
cd PaddleDetection/deploy/fastdeploy/rockchip/rknpu2/cpp
|
||||
# 注意:如果当前分支找不到下面的fastdeploy测试代码,请切换到develop分支
|
||||
# git checkout develop
|
||||
|
||||
# 编译部署示例
|
||||
mkdir build && cd build
|
||||
cmake .. -DFASTDEPLOY_INSTALL_DIR=${PWD}/fastdeploy-linux-x64-x.x.x
|
||||
make -j8
|
||||
|
||||
wget https://bj.bcebos.com/paddlehub/fastdeploy/rknpu2/ppyoloe_plus_crn_s_80e_coco.zip
|
||||
unzip ppyoloe_plus_crn_s_80e_coco.zip
|
||||
wget https://gitee.com/paddlepaddle/PaddleDetection/raw/release/2.4/demo/000000014439.jpg
|
||||
|
||||
# 运行部署示例
|
||||
# CPU推理
|
||||
./infer_demo ./ppyoloe_plus_crn_s_80e_coco 000000014439.jpg 0
|
||||
# RKNPU2推理
|
||||
./infer_demo ./ppyoloe_plus_crn_s_80e_coco 000000014439.jpg 1
|
||||
```
|
||||
|
||||
## 4. 更多指南
|
||||
RKNPU上对模型的输入要求是使用NHWC格式,且图片归一化操作会在转RKNN模型时,内嵌到模型中,因此我们在使用FastDeploy部署时,需要先调用DisableNormalizeAndPermute(C++)或`disable_normalize_and_permute(Python),在预处理阶段禁用归一化以及数据格式的转换。
|
||||
|
||||
- [Python部署](../python)
|
||||
- [转换PaddleDetection RKNN模型文档](../README.md)
|
||||
@@ -0,0 +1,96 @@
|
||||
// Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
|
||||
//
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
#include "fastdeploy/vision.h"
|
||||
|
||||
void ONNXInfer(const std::string& model_dir, const std::string& image_file) {
|
||||
std::string model_file = model_dir + "/ppyoloe_plus_crn_s_80e_coco.onnx";
|
||||
std::string params_file;
|
||||
std::string config_file = model_dir + "/infer_cfg.yml";
|
||||
auto option = fastdeploy::RuntimeOption();
|
||||
option.UseCpu();
|
||||
auto format = fastdeploy::ModelFormat::ONNX;
|
||||
|
||||
auto model = fastdeploy::vision::detection::PPYOLOE(
|
||||
model_file, params_file, config_file, option, format);
|
||||
|
||||
fastdeploy::TimeCounter tc;
|
||||
tc.Start();
|
||||
auto im = cv::imread(image_file);
|
||||
fastdeploy::vision::DetectionResult res;
|
||||
if (!model.Predict(im, &res)) {
|
||||
std::cerr << "Failed to predict." << std::endl;
|
||||
return;
|
||||
}
|
||||
auto vis_im = fastdeploy::vision::VisDetection(im, res, 0.5);
|
||||
tc.End();
|
||||
tc.PrintInfo("PPDet in ONNX");
|
||||
|
||||
std::cout << res.Str() << std::endl;
|
||||
cv::imwrite("infer_onnx.jpg", vis_im);
|
||||
std::cout << "Visualized result saved in ./infer_onnx.jpg" << std::endl;
|
||||
}
|
||||
|
||||
void RKNPU2Infer(const std::string& model_dir, const std::string& image_file) {
|
||||
auto model_file =
|
||||
model_dir + "/ppyoloe_plus_crn_s_80e_coco_rk3588_quantized.rknn";
|
||||
auto params_file = "";
|
||||
auto config_file = model_dir + "/infer_cfg.yml";
|
||||
|
||||
auto option = fastdeploy::RuntimeOption();
|
||||
option.UseRKNPU2();
|
||||
|
||||
auto format = fastdeploy::ModelFormat::RKNN;
|
||||
|
||||
auto model = fastdeploy::vision::detection::PPYOLOE(
|
||||
model_file, params_file, config_file, option, format);
|
||||
|
||||
model.GetPreprocessor().DisablePermute();
|
||||
model.GetPreprocessor().DisableNormalize();
|
||||
model.GetPostprocessor().ApplyNMS();
|
||||
|
||||
auto im = cv::imread(image_file);
|
||||
|
||||
fastdeploy::vision::DetectionResult res;
|
||||
fastdeploy::TimeCounter tc;
|
||||
tc.Start();
|
||||
if (!model.Predict(&im, &res)) {
|
||||
std::cerr << "Failed to predict." << std::endl;
|
||||
return;
|
||||
}
|
||||
tc.End();
|
||||
tc.PrintInfo("PPDet in RKNPU2");
|
||||
|
||||
std::cout << res.Str() << std::endl;
|
||||
auto vis_im = fastdeploy::vision::VisDetection(im, res, 0.5);
|
||||
cv::imwrite("infer_rknpu2.jpg", vis_im);
|
||||
std::cout << "Visualized result saved in ./infer_rknpu2.jpg" << std::endl;
|
||||
}
|
||||
|
||||
int main(int argc, char* argv[]) {
|
||||
if (argc < 4) {
|
||||
std::cout
|
||||
<< "Usage: infer_demo path/to/model_dir path/to/image run_option, "
|
||||
"e.g ./infer_demo ./model_dir ./test.jpeg"
|
||||
<< std::endl;
|
||||
return -1;
|
||||
}
|
||||
|
||||
if (std::atoi(argv[3]) == 0) {
|
||||
ONNXInfer(argv[1], argv[2]);
|
||||
} else if (std::atoi(argv[3]) == 1) {
|
||||
RKNPU2Infer(argv[1], argv[2]);
|
||||
}
|
||||
return 0;
|
||||
}
|
||||
@@ -0,0 +1,41 @@
|
||||
[English](README.md) | 简体中文
|
||||
# PaddleDetection RKNPU2 Python部署示例
|
||||
|
||||
本目录下用于展示PaddleDetection系列模型在RKNPU2上的部署,以下的部署过程以PPYOLOE为例子。
|
||||
|
||||
## 1. 部署环境准备
|
||||
在部署前,需确认以下步骤
|
||||
|
||||
- 1. 软硬件环境满足要求,RKNPU2环境部署等参考[FastDeploy环境要求](https://github.com/PaddlePaddle/FastDeploy/blob/develop/docs/cn/faq/rknpu2/rknpu2.md)
|
||||
|
||||
## 2. 部署模型准备
|
||||
|
||||
模型转换代码请参考[模型转换文档](../README.md)
|
||||
|
||||
## 3. 运行部署示例
|
||||
|
||||
本目录下提供`infer.py`快速完成PPYOLOE在RKNPU上部署的示例。执行如下脚本即可完成
|
||||
|
||||
```bash
|
||||
# 下载部署示例代码
|
||||
git clone https://github.com/PaddlePaddle/PaddleDetection.git
|
||||
cd PaddleDetection/deploy/fastdeploy/rockchip/rknpu2/python
|
||||
# 注意:如果当前分支找不到下面的fastdeploy测试代码,请切换到develop分支
|
||||
# git checkout develop
|
||||
|
||||
# 下载图片
|
||||
wget https://bj.bcebos.com/paddlehub/fastdeploy/rknpu2/ppyoloe_plus_crn_s_80e_coco.zip
|
||||
unzip ppyoloe_plus_crn_s_80e_coco.zip
|
||||
wget https://gitee.com/paddlepaddle/PaddleDetection/raw/release/2.4/demo/000000014439.jpg
|
||||
|
||||
# 运行部署示例
|
||||
python3 infer.py --model_file ./ppyoloe_plus_crn_s_80e_coco/ppyoloe_plus_crn_s_80e_coco_rk3588_quantized.rknn \
|
||||
--config_file ./ppyoloe_plus_crn_s_80e_coco/infer_cfg.yml \
|
||||
--image_file 000000014439.jpg
|
||||
```
|
||||
|
||||
# 4. 更多指南
|
||||
RKNPU上对模型的输入要求是使用NHWC格式,且图片归一化操作会在转RKNN模型时,内嵌到模型中,因此我们在使用FastDeploy部署时,需要先调用DisableNormalizeAndPermute(C++)或`disable_normalize_and_permute(Python),在预处理阶段禁用归一化以及数据格式的转换。
|
||||
|
||||
- [C++部署](../cpp)
|
||||
- [转换PaddleDetection RKNN模型文档](../README.md)
|
||||
@@ -0,0 +1,68 @@
|
||||
# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import fastdeploy as fd
|
||||
import cv2
|
||||
import os
|
||||
|
||||
|
||||
def parse_arguments():
|
||||
import argparse
|
||||
import ast
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument(
|
||||
"--model_file",
|
||||
default="./ppyoloe_plus_crn_s_80e_coco/ppyoloe_plus_crn_s_80e_coco_rk3588_quantized.rknn",
|
||||
help="Path of rknn model.")
|
||||
parser.add_argument(
|
||||
"--config_file",
|
||||
default="./ppyoloe_plus_crn_s_80e_coco/infer_cfg.yml",
|
||||
help="Path of config.")
|
||||
parser.add_argument(
|
||||
"--image_file",
|
||||
type=str,
|
||||
default="./000000014439.jpg",
|
||||
help="Path of test image file.")
|
||||
return parser.parse_args()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
args = parse_arguments()
|
||||
|
||||
model_file = args.model_file
|
||||
params_file = ""
|
||||
config_file = args.config_file
|
||||
|
||||
# setup runtime
|
||||
runtime_option = fd.RuntimeOption()
|
||||
runtime_option.use_rknpu2()
|
||||
|
||||
model = fd.vision.detection.PPYOLOE(
|
||||
model_file,
|
||||
params_file,
|
||||
config_file,
|
||||
runtime_option=runtime_option,
|
||||
model_format=fd.ModelFormat.RKNN)
|
||||
model.preprocessor.disable_normalize()
|
||||
model.preprocessor.disable_permute()
|
||||
model.postprocessor.apply_nms()
|
||||
|
||||
# predict
|
||||
im = cv2.imread(args.image_file)
|
||||
result = model.predict(im)
|
||||
print(result)
|
||||
|
||||
# visualize
|
||||
vis_im = fd.vision.vis_detection(im, result, score_threshold=0.5)
|
||||
cv2.imwrite("visualized_result.jpg", vis_im)
|
||||
print("Visualized result save in ./visualized_result.jpg")
|
||||
17
paddle_detection/deploy/fastdeploy/rockchip/rv1126/README.md
Normal file
17
paddle_detection/deploy/fastdeploy/rockchip/rv1126/README.md
Normal file
@@ -0,0 +1,17 @@
|
||||
[English](README.md) | 简体中文
|
||||
|
||||
# PaddleDetection 检测模型在瑞芯微NPU上的部署方案-FastDeploy
|
||||
|
||||
## 1. 说明
|
||||
本示例基于RV1126来介绍如何使用FastDeploy部署PaddleDetection模型,支持如下芯片的部署:
|
||||
- Rockchip RV1109
|
||||
- Rockchip RV1126
|
||||
- Rockchip RK1808
|
||||
|
||||
模型的量化和量化模型的下载请参考:[模型量化](../../quantize/README.md)
|
||||
|
||||
## 详细部署文档
|
||||
|
||||
在 RV1126 上只支持 C++ 的部署。
|
||||
|
||||
- [C++部署](cpp)
|
||||
@@ -0,0 +1,27 @@
|
||||
PROJECT(infer_demo C CXX)
|
||||
CMAKE_MINIMUM_REQUIRED (VERSION 3.10)
|
||||
|
||||
option(FASTDEPLOY_INSTALL_DIR "Path of downloaded fastdeploy sdk.")
|
||||
|
||||
include(${FASTDEPLOY_INSTALL_DIR}/FastDeploy.cmake)
|
||||
|
||||
include_directories(${FASTDEPLOY_INCS})
|
||||
include_directories(${FastDeploy_INCLUDE_DIRS})
|
||||
|
||||
add_executable(infer_demo ${PROJECT_SOURCE_DIR}/infer.cc)
|
||||
target_link_libraries(infer_demo ${FASTDEPLOY_LIBS})
|
||||
|
||||
set(CMAKE_INSTALL_PREFIX ${CMAKE_SOURCE_DIR}/build/install)
|
||||
|
||||
install(TARGETS infer_demo DESTINATION ./)
|
||||
|
||||
install(DIRECTORY models DESTINATION ./)
|
||||
install(DIRECTORY images DESTINATION ./)
|
||||
|
||||
file(GLOB_RECURSE FASTDEPLOY_LIBS ${FASTDEPLOY_INSTALL_DIR}/lib/lib*.so*)
|
||||
file(GLOB_RECURSE ALL_LIBS ${FASTDEPLOY_INSTALL_DIR}/third_libs/install/lib*.so*)
|
||||
list(APPEND ALL_LIBS ${FASTDEPLOY_LIBS})
|
||||
install(PROGRAMS ${ALL_LIBS} DESTINATION lib)
|
||||
|
||||
file(GLOB ADB_TOOLS run_with_adb.sh)
|
||||
install(PROGRAMS ${ADB_TOOLS} DESTINATION ./)
|
||||
@@ -0,0 +1,64 @@
|
||||
[English](README.md) | 简体中文
|
||||
# PaddleDetection 量化模型 RV1126 C++ 部署示例
|
||||
|
||||
本目录下提供的 `infer.cc`,可以帮助用户快速完成 PP-YOLOE 量化模型在 RV1126 上的部署推理加速。
|
||||
|
||||
## 1. 部署环境准备
|
||||
### 1.1 FastDeploy 交叉编译环境准备
|
||||
软硬件环境满足要求,以及交叉编译环境的准备,请参考:[瑞芯微RV1126部署环境](https://github.com/PaddlePaddle/FastDeploy/blob/develop/docs/cn/build_and_install#自行编译安装)
|
||||
|
||||
## 2. 部署模型准备
|
||||
1. 用户可以直接使用由 FastDeploy 提供的量化模型进行部署。
|
||||
2. 用户可以先使用 PaddleDetection 自行导出 Float32 模型,注意导出模型模型时设置参数:use_shared_conv=False,更多细节请参考:[PP-YOLOE](https://github.com/PaddlePaddle/PaddleDetection/tree/release/2.4/configs/ppyoloe)
|
||||
3. 用户可以使用 FastDeploy 提供的[一键模型自动化压缩工具](https://github.com/PaddlePaddle/FastDeploy/blob/develop/tools/common_tools/auto_compression/),自行进行模型量化, 并使用产出的量化模型进行部署。(注意: 推理量化后的检测模型仍然需要FP32模型文件夹下的 infer_cfg.yml 文件,自行量化的模型文件夹内不包含此 yaml 文件,用户从 FP32 模型文件夹下复制此yaml文件到量化后的模型文件夹内即可。)
|
||||
4. 模型需要异构计算,异构计算文件可以参考:[异构计算](https://github.com/PaddlePaddle/FastDeploy/blob/develop/docs/cn/faq/heterogeneous_computing_on_timvx_npu.md),由于 FastDeploy 已经提供了模型,可以先测试我们提供的异构文件,验证精度是否符合要求。
|
||||
|
||||
更多量化相关相关信息可查阅[模型量化](../../../quantize/README.md)
|
||||
|
||||
## 3. 运行部署示例
|
||||
请按照以下步骤完成在 RV1126 上部署 PP-YOLOE 量化模型:
|
||||
1. 交叉编译编译 FastDeploy 库,具体请参考:[交叉编译 FastDeploy](https://github.com/PaddlePaddle/FastDeploy/blob/develop/docs/cn/build_and_install/rv1126.md)
|
||||
|
||||
2. 将编译后的库拷贝到当前目录,可使用如下命令:
|
||||
```bash
|
||||
cp -r FastDeploy/build/fastdeploy-timvx/ PaddleDetection/deploy/fastdeploy/rockchip/rv1126/cpp
|
||||
```
|
||||
|
||||
3. 在当前路径下载部署所需的模型和示例图片:
|
||||
```bash
|
||||
cd PaddleDetection/deploy/fastdeploy/rockchip/rv1126/cpp
|
||||
mkdir models && mkdir images
|
||||
wget https://bj.bcebos.com/fastdeploy/models/ppyoloe_noshare_qat.tar.gz
|
||||
tar -xvf ppyoloe_noshare_qat.tar.gz
|
||||
cp -r ppyoloe_noshare_qat models
|
||||
wget https://gitee.com/paddlepaddle/PaddleDetection/raw/release/2.4/demo/000000014439.jpg
|
||||
cp -r 000000014439.jpg images
|
||||
```
|
||||
|
||||
4. 编译部署示例,可使入如下命令:
|
||||
```bash
|
||||
cd PaddleDetection/deploy/fastdeploy/rockchip/rv1126/cpp
|
||||
mkdir build && cd build
|
||||
cmake -DCMAKE_TOOLCHAIN_FILE=${PWD}/../fastdeploy-timvx/toolchain.cmake -DFASTDEPLOY_INSTALL_DIR=${PWD}/../fastdeploy-timvx -DTARGET_ABI=armhf ..
|
||||
make -j8
|
||||
make install
|
||||
# 成功编译之后,会生成 install 文件夹,里面有一个运行 demo 和部署所需的库
|
||||
```
|
||||
|
||||
5. 基于 adb 工具部署 PP-YOLOE 检测模型到 Rockchip RV1126,可使用如下命令:
|
||||
```bash
|
||||
# 进入 install 目录
|
||||
cd PaddleDetection/deploy/fastdeploy/rockchip/rv1126/cpp/build/install/
|
||||
# 如下命令表示:bash run_with_adb.sh 需要运行的demo 模型路径 图片路径 设备的DEVICE_ID
|
||||
bash run_with_adb.sh infer_demo ppyoloe_noshare_qat 000000014439.jpg $DEVICE_ID
|
||||
```
|
||||
|
||||
部署成功后运行结果如下:
|
||||
|
||||
<img width="640" src="https://user-images.githubusercontent.com/30516196/203708564-43c49485-9b48-4eb2-8fe7-0fa517979fff.png">
|
||||
|
||||
需要特别注意的是,在 RV1126 上部署的模型需要是量化后的模型,模型的量化请参考:[模型量化](https://github.com/PaddlePaddle/FastDeploy/blob/develop/docs/cn/quantize.md)
|
||||
|
||||
## 4. 更多指南
|
||||
- [PaddleDetection C++ API文档](https://www.paddlepaddle.org.cn/fastdeploy-api-doc/cpp/html/namespacefastdeploy_1_1vision_1_1detection.html)
|
||||
- [FastDeploy部署PaddleDetection模型概览](../../)
|
||||
@@ -0,0 +1,66 @@
|
||||
// Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
|
||||
//
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
#include "fastdeploy/vision.h"
|
||||
#ifdef WIN32
|
||||
const char sep = '\\';
|
||||
#else
|
||||
const char sep = '/';
|
||||
#endif
|
||||
|
||||
void InitAndInfer(const std::string& model_dir, const std::string& image_file) {
|
||||
auto model_file = model_dir + sep + "model.pdmodel";
|
||||
auto params_file = model_dir + sep + "model.pdiparams";
|
||||
auto config_file = model_dir + sep + "infer_cfg.yml";
|
||||
auto subgraph_file = model_dir + sep + "subgraph.txt";
|
||||
fastdeploy::vision::EnableFlyCV();
|
||||
fastdeploy::RuntimeOption option;
|
||||
option.UseTimVX();
|
||||
option.paddle_lite_option.nnadapter_subgraph_partition_config_path =
|
||||
subgraph_file
|
||||
|
||||
auto model = fastdeploy::vision::detection::PPYOLOE(model_file, params_file,
|
||||
config_file, option);
|
||||
assert(model.Initialized());
|
||||
|
||||
auto im = cv::imread(image_file);
|
||||
|
||||
fastdeploy::vision::DetectionResult res;
|
||||
if (!model.Predict(im, &res)) {
|
||||
std::cerr << "Failed to predict." << std::endl;
|
||||
return;
|
||||
}
|
||||
|
||||
std::cout << res.Str() << std::endl;
|
||||
|
||||
auto vis_im = fastdeploy::vision::VisDetection(im, res, 0.5);
|
||||
cv::imwrite("vis_result.jpg", vis_im);
|
||||
std::cout << "Visualized result saved in ./vis_result.jpg" << std::endl;
|
||||
|
||||
}
|
||||
|
||||
int main(int argc, char* argv[]) {
|
||||
if (argc < 3) {
|
||||
std::cout << "Usage: infer_demo path/to/quant_model "
|
||||
"path/to/image "
|
||||
"e.g ./infer_demo ./PPYOLOE_L_quant ./test.jpeg"
|
||||
<< std::endl;
|
||||
return -1;
|
||||
}
|
||||
|
||||
std::string model_dir = argv[1];
|
||||
std::string test_image = argv[2];
|
||||
InitAndInfer(model_dir, test_image);
|
||||
return 0;
|
||||
}
|
||||
@@ -0,0 +1,47 @@
|
||||
#!/bin/bash
|
||||
HOST_SPACE=${PWD}
|
||||
echo ${HOST_SPACE}
|
||||
WORK_SPACE=/data/local/tmp/test
|
||||
|
||||
# The first parameter represents the demo name
|
||||
DEMO_NAME=image_classification_demo
|
||||
if [ -n "$1" ]; then
|
||||
DEMO_NAME=$1
|
||||
fi
|
||||
|
||||
# The second parameter represents the model name
|
||||
MODEL_NAME=mobilenet_v1_fp32_224
|
||||
if [ -n "$2" ]; then
|
||||
MODEL_NAME=$2
|
||||
fi
|
||||
|
||||
# The third parameter indicates the name of the image to be tested
|
||||
IMAGE_NAME=0001.jpg
|
||||
if [ -n "$3" ]; then
|
||||
IMAGE_NAME=$3
|
||||
fi
|
||||
|
||||
# The fourth parameter represents the ID of the device
|
||||
ADB_DEVICE_NAME=
|
||||
if [ -n "$4" ]; then
|
||||
ADB_DEVICE_NAME="-s $4"
|
||||
fi
|
||||
|
||||
# Set the environment variables required during the running process
|
||||
EXPORT_ENVIRONMENT_VARIABLES="export GLOG_v=5; export VIV_VX_ENABLE_GRAPH_TRANSFORM=-pcq:1; export VIV_VX_SET_PER_CHANNEL_ENTROPY=100; export TIMVX_BATCHNORM_FUSION_MAX_ALLOWED_QUANT_SCALE_DEVIATION=300000; export VSI_NN_LOG_LEVEL=5;"
|
||||
|
||||
EXPORT_ENVIRONMENT_VARIABLES="${EXPORT_ENVIRONMENT_VARIABLES}export LD_LIBRARY_PATH=${WORK_SPACE}/lib:\$LD_LIBRARY_PATH;"
|
||||
|
||||
# Please install adb, and DON'T run this in the docker.
|
||||
set -e
|
||||
adb $ADB_DEVICE_NAME shell "rm -rf $WORK_SPACE"
|
||||
adb $ADB_DEVICE_NAME shell "mkdir -p $WORK_SPACE"
|
||||
|
||||
# Upload the demo, librarys, model and test images to the device
|
||||
adb $ADB_DEVICE_NAME push ${HOST_SPACE}/lib $WORK_SPACE
|
||||
adb $ADB_DEVICE_NAME push ${HOST_SPACE}/${DEMO_NAME} $WORK_SPACE
|
||||
adb $ADB_DEVICE_NAME push models $WORK_SPACE
|
||||
adb $ADB_DEVICE_NAME push images $WORK_SPACE
|
||||
|
||||
# Execute the deployment demo
|
||||
adb $ADB_DEVICE_NAME shell "cd $WORK_SPACE; ${EXPORT_ENVIRONMENT_VARIABLES} chmod +x ./${DEMO_NAME}; ./${DEMO_NAME} ./models/${MODEL_NAME} ./images/$IMAGE_NAME"
|
||||
Reference in New Issue
Block a user